| RQV30034 | |
| I. Background | |
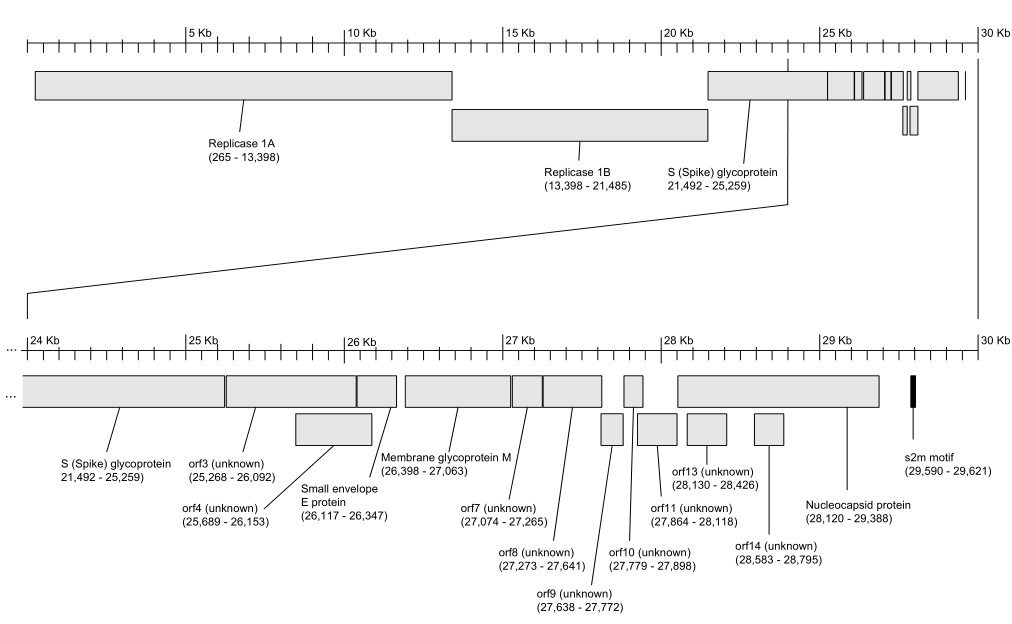
Severe acute respiratory syndrome (SARS) was first reported in Asia in February 2003, and then spread to more than a dozen countries around the world. SARS is a type of coronavirus that has a capsule and a linear single-stranded genome. The corresponding structure diagram of the RNA virus is as follows:
According to the introduction of CDC and WHO, nucleic acid diagnosis for SARS is generally for ORF1ab/RdRP (RNA-dependent RNA polymerase), Gene N, Gene M, and Gene E. Gene S is more used for the development of corresponding drugs and vaccines. The sequence included in NCBI is NC_004718.3, with a total length of 29751bp, and the gene encodes 4 structural proteins: S, M, N and E. The detection limit of the kit is the biggest cause of false negatives. Therefore, for the detection limit of diagnostic products, we need to carefully evaluate the performance of each kit. In the past, performance evaluation for detection limits generally selected in vitro transcribed RNA or clinically positive viruses as standard products for performance evaluation. However, both have obvious certainty. First, the RNA transcribed in vitro is generally very pure and single, does not involve extraction, and does not meet the microenvironment of the clinical virus. Therefore, the detection sensitivity will inevitably be overestimated. This is also a high probability of false The main reason for the negative; clinically positive virus again, even if it is an inactivated virus, still has a great biological safety hazard. Therefore, the laboratory level is required to be P3-P4. Most of the units that develop diagnostic kits do not meet the requirements. The source of clinically positive viruses is also very limited and cannot be stably supplied, and is repeatedly used for performance evaluation of the kit. | |
| II.product description | |
It has the complete envelope structure of the virus and the nucleic acid sequence corresponding to SARS, but the pseudovirus standard product with low biosafety risk perfectly overcomes the shortcomings of choosing in vitro transcribed RNA or clinically positive virus as the standard product. It is very suitable Standards for evaluation of nucleic acid diagnostic performance. Construction process: SARS gene synthesis → pseudovirus packaging → purification → QC detection (ddPCR) | |
| III. product description | |
| product name: | SARS-Panel Pseudovirus Standard Reference |
| Corresponding sequence (see appendix for details): | ORF1ab/RdRP(2795bp)、Gene N(1207bp) |
| Specifications: | 1ml |
| Number of copies: | |
| Biosafety level: | P2 |
| Transportation and storage methods: | Dry ice transportation, -80°C save |
| Validity period: | |
| IV. Product usage and advantages | |
| Product Usage: | SARS Performance evaluation of diagnostic kits |
| Product advantages: | ·The SARS pseudovirus standard product is different from the RNA synthesized in vitro and clinically positive live virus. It perfectly overcomes the shortcomings of both, and is really suitable for performance evaluation of the kit, including detection limit, specificity, repeatability, etc.; ·According to the characteristics of SARS coronavirus, a total of 2 segments of ORF1ab/RdRP (RNA-dependent RNA polymerase) and Gene N (nucleocapsid phosphoprotein) were selected for the packaging of pseudoviruses, which well characterized the characteristics of SARS sequence; ·Coby Bio has designed the primers and probe sequences of the ddPCR system, which can complete the QC copy number detection of pseudovirus without constructing a standard curve, which can very accurately characterize the copy number of the standard product, and overcome the Q-PCR analysis of CT Inaccuracy of the relative judgment standard of the value; ·Pseudovirus standard products, non-pathogenic, renewable, reliable quality control methods, stable between batches, can be prepared and supplied stably for a long time, and require laboratory biosafety level P2 to meet the safety needs of many organizations. |
| Ⅴ. appendix | |
ORF1ab/RdRP: TCTGCGGATGCATCAACGTTTTTAAACGGGTTTGCGGTGTAAGTGCAGCCCGTCTTACACCGTGCGGCACAGGCACTAGTACTGATGTCGTCTACAGGGCTTTTGATATTTACAACGAAAAAGTTGCT GGTTTTGCAAAGTTCCTAAAAACTAATTGCTGTCGCTTCCAGGAGAAGGATGAGGAAGGCAATTTATTAGACTCTTACTTTGTAGTTAAGAGGCATACTATGTCTAACTACCAACATGAAGAGACTAT TTATAACTTGGTTAAAGATTGTCCAGCGGTTGCTGTCCATGACTTTTTCAAGTTTAGAGTAGATGGTGACATGGTACCACATATATCACGTCAGCGTCTAACTAAATACACAATGGCTGATTTAGTCT ATGCTCTACGTCATTTTGATGAGGGTAATTGTGATACATTAAAAGAAATACTCGTCACATACAATTGCTGTGATGATGATTATTTCAATAAGAAGGATTGGTATGACTTCGTAGAGAATCCTGACATC TTACGCGTATATGCTAACTTAGGTGAGCGTGTACGCCAATCATTATTAAAGACTGTACAATTCTGCGATGCTATGCGTGATGCAGGCATTGTAGGCGTACTGACATTAGATAATCAGGATCTTAATGG GAACTGGTACGATTTCGGTGATTTCGTACAAGTAGCACCAGGCTGCGGAGTTCCTATTGTGGATTCATATTACTCATTGCTGATGCCCATCCTCACTTTGACTAGGGCATTGGCTGCTGAGTCCCATA TGGATGCTGATCTCGCAAAACCACTTATTAAGTGGGATTTGCTGAAATATGATTTTACGGAAGAGAGACTTTGTCTCTTCGACCGTTATTTTAAATATTGGGACCAGACATACCATCCCAATTGTATT AACTGTTTGGATGATAGGTGTATCCTTCATTGTGCAAACTTTAATGTGTTATTTTCTACTGTGTTTCCACCTACAAGTTTTGGACCACTAGTAAGAAAAATATTTGTAGATGGTGTTCCTTTTGTTGT TTCAACTGGATACCATTTTCGTGAGTTAGGAGTCGTACATAATCAGGATGTAAACTTACATAGCTCGCGTCTCAGTTTCAAGGAACTTTTAGTGTATGCTGCTGATCCAGCTATGCATGCAGCTTCTG GCAATTTATTGCTAGATAAACGCACTACATGCTTTTCAGTAGCTGCACTAACAAACAATGTTGCTTTTCAAACTGTCAAACCCGGTAATTTTAATAAAGACTTTTATGACTTTGCTGTGTCTAAAGGT TTCTTTAAGGAAGGAAGTTCTGTTGAACTAAAACACTTCTTCTTTGCTCAGGATGGCAACGCTGCTATCAGTGATTATGACTATTATCGTTATAATCTGCCAACAATGTGTGATATCAGACAACTCCT ATTCGTAGTTGAAGTTGTTGATAAATACTTTGATTGTTACGATGGTGGCTGTATTAATGCCAACCAAGTAATCGTTAACAATCTGGATAAATCAGCTGGTTTCCCATTTAATAAATGGGGTAAGGCTA GACTTTATTATGACTCAATGAGTTATGAGGATCAAGATGCACTTTTCGCGTATACTAAGCGTAATGTCATCCCTACTATAACTCAAATGAATCTTAAGTATGCCATTAGTGCAAAGAATAGAGCTCGC ACCGTAGCTGGTGTCTCTATCTGTAGTACTATGACAAATAGACAGTTTCATCAGAAATTATTGAAGTCAATAGCCGCCACTAGAGGAGCTACTGTGGTAATTGGAACAAGCAAGTTTTACGGTGGCTG GCATAATATGTTAAAAACTGTTTACAGTGATGTAGAAACTCCACACCTTATGGGTTGGGATTATCCAAAATGTGACAGAGCCATGCCTAACATGCTTAGGATAATGGCCTCTCTTGTTCTTGCTCGCA AACATAACACTTGCTGTAACTTATCACACCGTTTCTACAGGTTAGCTAACGAGTGTGCGCAAGTATTAAGTGAGATGGTCATGTGTGGCGGCTCACTATATGTTAAACCAGGTGGAACATCATCCGGT GATGCTACAACTGCTTATGCTAATAGTGTCTTTAACATTTGTCAAGCTGTTACAGCCAATGTAAATGCACTTCTTTCAACTGATGGTAATAAGATAGCTGACAAGTATGTCCGCAATCTACAACACAG GCTCTATGAGTGTCTCTATAGAAATAGGGATGTTGATCATGAATTCGTGGATGAGTTTTACGCTTACCTGCGTAAACATTTCTCCATGATGATTCTTTCTGATGATGCCGTTGTGTGCTATAACAGTA ACTATGCGGCTCAAGGTTTAGTAGCTAGCATTAAGAACTTTAAGGCAGTTCTTTATTATCAAAATAATGTGTTCATGTCTGAGGCAAAATGTTGGACTGAGACTGACCTTACTAAAGGACCTCACGAA TTTTGCTCACAGCATACAATGCTAGTTAAACAAGGAGATGATTACGTGTACCTGCCTTACCCAGATCCATCAAGAATATTAGGCGCAGGCTGTTTTGTCGATGATATTGTCAAAACAGATGGTACACT TATGATTGAAAGGTTCGTGTCACTGGCTATTGATGCTTACCCACTTACAAAACATCCTAATCAGGAGTATGCTGATGTCTTTCACTTGTATTTACAATACATTAGAAAGTTACATGATGAGCTTACTG GCCACATGTTGGACATGTATTCCGTAATGCTAACTAATGATAACACCTCACGGTACTGGGAACCTGAGTTTTATGAGGCTATGTACACACCACATACAGTCTTGCAG
Gene N: ATGTCTGATAATGGACCCCAATCAAACCAACGTAGTGCCCCCCGCATTACATTTGGTGGACCCACAGATTCAACTGACAATAACCAGAATGGAGGACGCAATGGGGCAAGGCCAAAACAGCGCCGACC CCAAGGTTTACCCAATAATACTGCGTCTTGGTTCACAGCTCTCACTCAGCATGGCAAGGAGGAACTTAGATTCCCTCGAGGCCAGGGCGTTCCAATCAACACCAATAGTGGTCCAGATGACCAAATTG GCTACTACCGAAGAGCTACCCGACGAGTTCGTGGTGGTGACGGCAAAATGAAAGAGCTCAGCCCCAGATGGTACTTCTATTACCTAGGAACTGGCCCAGAAGCTTCACTTCCCTACGGCGCTAACAAA GAAGGCATCGTATGGGTTGCAACTGAGGGAGCCTTGAATACACCCAAAGACCACATTGGCACCCGCAATCCTAATAACAATGCTGCCACCGTGCTACAACTTCCTCAAGGAACAACATTGCCAAAAGG CTTCTACGCAGAGGGAAGCAGAGGCGGCAGTCAAGCCTCTTCTCGCTCCTCATCACGTAGTCGCGGTAATTCAAGAAATTCAACTCCTGGCAGCAGTAGGGGAAATTCTCCTGCTCGAATGGCTAGCG GAGGTGGTGAAACTGCCCTCGCGCTATTGCTGCTAGACAGATTGAACCAGCTTGAGAGCAAAGTTTCTGGTAAAGGCCAACAACAACAAGGCCAAACTGTCACTAAGAAATCTGCTGCTGAGGCATCT AAAAAGCCTCGCCAAAAACGTACTGCCACAAAACAGTACAACGTCACTCAAGCATTTGGGAGACGTGGTCCAGAACAAACCCAAGGAAATTTCGGGGACCAAGACCTAATCAGACAAGGAACTGATTA CAAACATTGGCCGCAAATTGCACAATTTGCTCCAAGTGCCTCTGCATTCTTTGGAATGTCACGCATTGGCATGGAAGTCACACCTTCGGGAACATGGCTGACTTATCATGGAGCCATTAAATTGGATG ACAAAGATCCACAATTCAAAGACAACGTCATACTGCTGAACAAGCACATTGACGCATACAAAACATTCCCACCAACAGAGCCTAAAAAGGACAAAAAGAAAAAGACTGATGAAGCTCAGCCTTTGCCG CAGAGACAAAAGAAGCAGCCCACTGTGACTCTTCTTCCTGCGGCTGACATGGATGATTTCTCCAGACAACTTCAAAATTCCATGAGTGGAGCTTCTGCTGATTCAACTCAGGCATAA | |
E-mail:sales@reqbio.com
Add:3rd Floor, No. 6, Lane 222,
Guangdan Road, Pudong New Area,
Shanghai,China

WeChat public account